When we were talking to working data scientists and data engineers here in Nashville about designing a data science program there were several things that people consistently identified as being important if we were going to familiarize students with what it is like to work in a real data analytics/data science job. One of the things we heard was that Data Science in the real world is messy because the real world is messy. Data in the real world is never clean and/or complete and/or consistent or any of the other things it needs to be for our modeling techniques or predictive techniques to work.
Based on the input we received, we have designed into our curriculum and projects the idea that we need to teach the entire data science process, not just the fun/cool machine learning and statistical modeling pieces of the process.
I was reminded of all of this last week when in my reading I came across a Linkedin post by Maciek Wasiak titled “Data Science is Not Taught at Universities - and Here is Why”.
The author taught data science at a university for several years and now works on real world data science projects, so it’s an informed, albeit opinionated, view of the problem. Here are a couple of excerpts that speak to the point of this blog post:
Maybe in the lab, you were handed over a nice Modelling Table to load it to R or SAS Enterprise Miner but in real life that almost never happens. Your source will be a database with tens or hundreds of tables, millions of records, usually after 3 painful migrations with gaps in history, columns without descriptions and with no one around to answer your questions. That’s right, we're not in Kansas anymore. ... If you think there is a team of SQL developers waiting to build that table for you – you are delusional. It's all on you. We code SQL, test SQL and debug SQL for 70%-90% of project time. Sometimes it’s SAS, more recently hacking around with Java or Python. If you haven’t done Feature Engineering from messy relational data sources – it means you have no idea what to do for this most important part of the Predictive Modelling project.
And more…
Universities focus on machine learning techniques (i.e. the Modelling phase only) because this is the cool stuff. They do not want to engage in researching and teaching the much more important Data Preparation process because it looks so uncool in comparison. Even its name sucks. In a university lab everyone runs neural networks. No one writes the feature-generating SQL. This approach massively skews students’ understanding of the future job. They learn that Advanced Analytics means playing with Artificial Intelligence in R all day long. When they find out that it takes months of repetitive coding, requires psychological stamina of an A&E surgeon and a paramount attention to detail – they are confused, disappointed and frustrated.
The Data Science literature has several different views of the process of addressing a data science question. One well known one mentioned in the Linkedin post is CRISP-DM. We’ve looked at these various models and the one we’ve chosen to work with as our primary view of the Data Science process is the one pictured below, taken from “Doing Data Science” by O’Neil and Schutt. The reason we’re fans of this process model is because it better presents the relative importance of the various steps associated with data preparation and understanding in the context of an overall project.
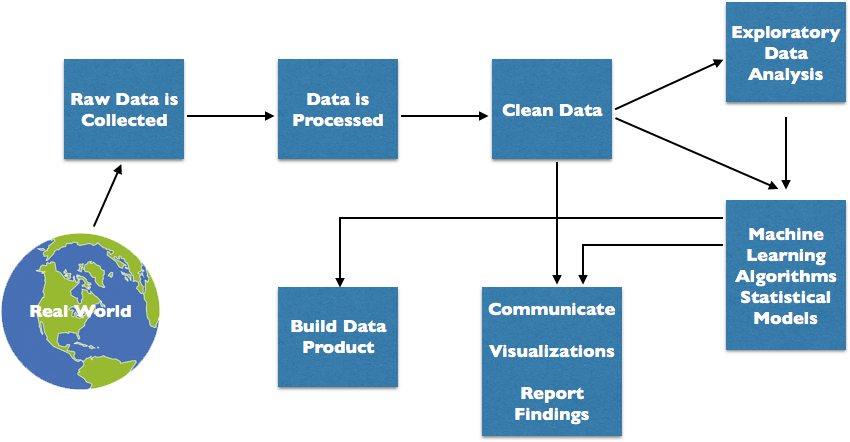
While we like the explicit identification of multiple data related steps in the model above, we do see one weakness in this representation. This model doesn’t capture the iterative nature of the typical data science project quite as well as some of the other representations that we have seen.
One representation that does capture the iterative nature of data science projects is the one below. I really like the way this representation emphasizes the iterative nature of the process and the way in which we’re trying to answer questions and solve problems with every step we take through a project.
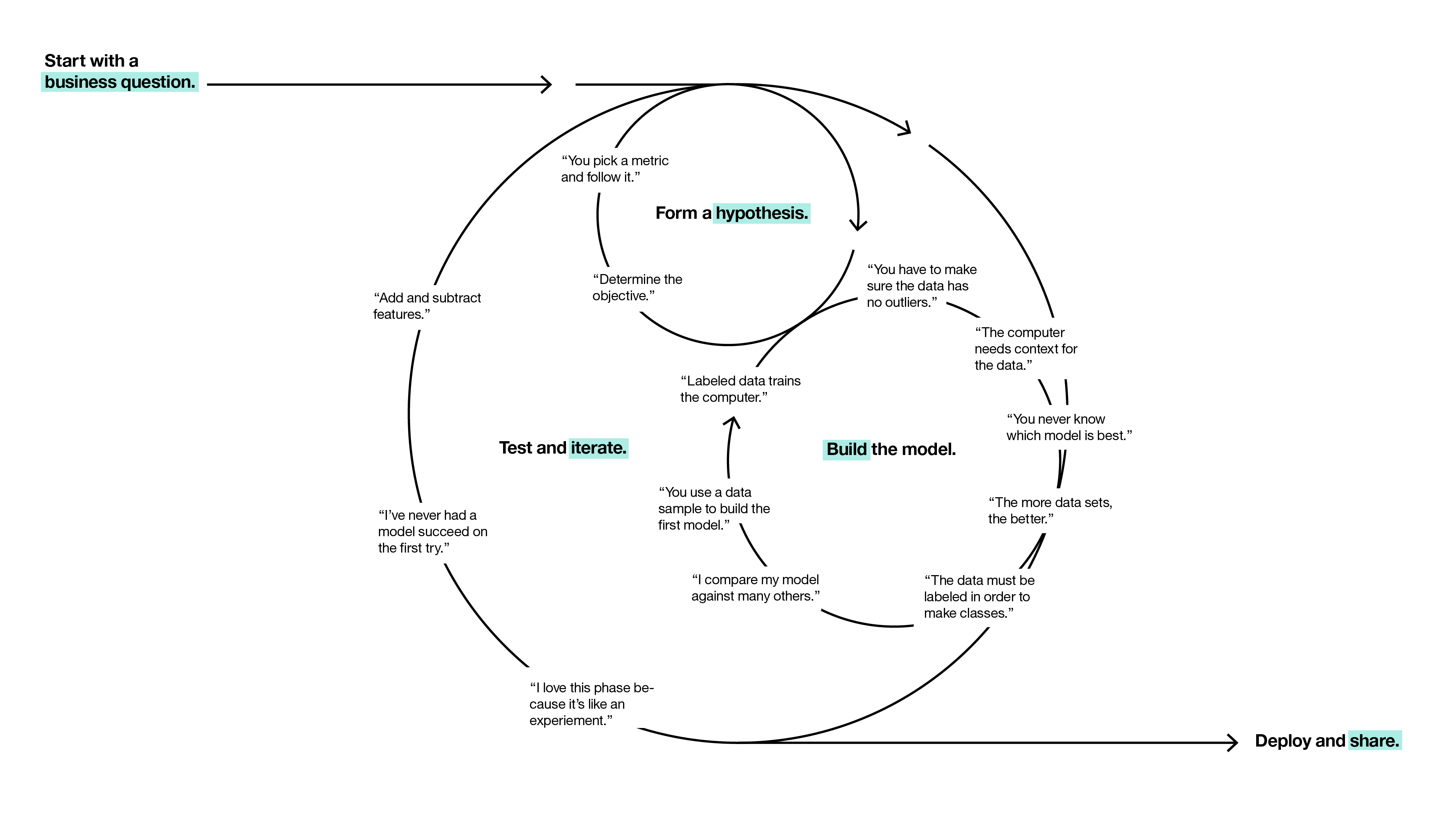
Source for the diagram above here.
We’re going to do our best to have our Data Science Bootcamp students experience both of these aspects of the real-world data science project. We’re setting up projects so that students must work through the process of getting the data ready before they can just dive into exploratory data analysis/modeling. We’re working with companies in Nashville to source projects and data that will confront our students with the messiness and uncertainty they will need to deal with once they get into real data science jobs. We’re trying to design projects that force an iterative exploration and refinement of their understanding of the business question, their starting hypothesis, the data, etc.
That’s really one of the things we see as central to what makes us different than an academic program. We’re trying to as best we can prepare our students for what it will take to become productive in a job as a data analyst, data scientist or data engineer. Which make sense - we’re a vocational school and don’t pretend to be otherwise. That’s a different job than a university. That doesn’t mean our students won’t learn the modeling and machine learning and other “fun” stuff in data science. But they will also learn other things that we hope will better prepare them to become rapidly productive on the job. That’s what we have been doing in the web development/software development world for the past five years. Time to apply what we’ve learned to another exciting, growing field.





