Students in Data Science Cohort 4 have recently been studying machine learning, and to practice what they’ve been learning they took part in a competition hosted on Kaggle.com. Kaggle is a community of data scientists and machine learning practitioners, and is well-known for hosting machine learning competitions which offer thousands of dollars to the teams that are able to make the best machine learning algorithm for a given problem. Traditionally, our data science cohorts have worked on public Kaggle competitions, but since there were no open competitions that would be appropriate for beginners, they worked on a private, in-class competition.
For our competition, the student groups were tasked with building a model to predict the permeability, or ease of fluid flow, through synthetic microstructures. The following image from nature.com shows one such microstructure with a simulated fluid flow. Areas of fast and slow flow are indicated by blue and red lines, respectively.

The dataset came from research published in Scientific Reports (Röding, M., Ma, Z. & Torquato, S. Predicting permeability via statistical learning on higher-order microstructural information. Sci Rep 10, 15239 (2020)).
Students were given 290 different measurements associated with each microstructure, including the porosity (how much of the structure consisted of pores) and the tortuosity (how twisted those pores are). Students first took some time to explore the relationship between the predictors and target variable, uncovering, for example, that permeability increases with increased porosity but decreases with increased tortuosity.
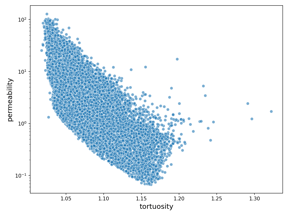
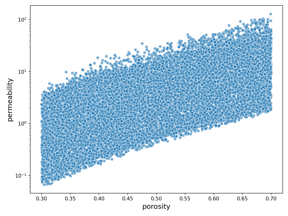
The chart on the left visualizes their findings that increased tortuosity decreases permeability. The chart on the right, adapted from Savannah Sew-Hee’s, DS4 student, EDA notebook, visualizes their findings that permeability increases with increased porosity.
Students took a variety of approaches to the problem at hand. One group tried applying principal components analysis (PCA), a technique that synthesizes a large number of measurements into a smaller number of features that capture most of the original information. Maeva Ralafiarindaza explains, “looking at how many columns we had, and that most of them were related to each other, my first reaction was that we can reduce them somehow.” As displayed in the image below, the team was able to boil down the almost 300 features into just 3 that still captured 99.5% of the original variability. As a bonus, these features were still informative as far as the ultimate goal of predicting permeability, as indicated by the color of the points. Patti Daily, another member of this team, describes how they tried a number of models but ultimately found the most success with the PCA approach. “I was certain that one of the more powerful models - like Random Forest, Extra Trees, Neural Networks, etc would be the best approach.” However, “as we kept regrouping, our findings were that the original PCA models with regression were having better results.”
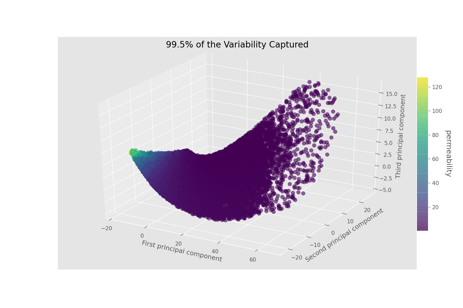
This 3D scatterplot was adapted from DS4 student Patti Daily’s PCA notebook.
Other groups took this competition as an opportunity to learn more about building neural network models using the keras library. According to Alvin Wendt, “I knew about the theoretical concept behind the neural networks and how powerful they are but have never worked with the tools to try them out.” Alvin and teammate Anthony Gertz tried a large number of different model configurations to try and improve their score. “Our team was very competitive during the competition and created a running spreadsheet to track all the changes in the features and parameters to see what it did for the predictions.” Students discovered that a large part of building machine learning models is carefully organizing and managing your workflow. As Anthony explains, “make sure your fundamental inputs and outputs are correct. It’s very easy to mistakenly standardize/normalize/scale data in one step of the process and miss it in the other.”
Data-SAVvy-Rocks, the team that ultimately achieved the best results, started by doing extensive exploratory data analysis. According to Armelle Le Guelte, “before diving into the model-building process, we took a look at the data to assess the skew of the target and predictor variables.” This exploration helped them to “zero-in early on using the log of permeability as our target variable.” While most teams stuck to Python’s scikit-learn library, this team initially made use of the R programming language to perform statistical analysis on the predictor variables, looking for those which had statistically-significant predictive power on the log of permeability.
With a good grasp on the dataset, Data-SAVvy-Rocks then took to building a large number of different models, including polynomial regression, random forests, and neural networks. Veronica Ikeshoji-Orlati describes the team’s approach, “we also tried to be as methodical as possible with our submissions - focusing on different methods, comparing the results as we went, and taking the time to reflect on what was working better or worse and asking why that might have been the case.”
To generate the winning predictions, this team used a combination of five different models, a technique known as ensembling and one which is commonly used by winning Kaggle teams. While it can produce predictions that do well on the scoreboard, Savannah Sew-Hee recognizes that such a layered approach does have limited practical utility. “For its complexity, the final improvements in score were so small that in the real world it would be more beneficial to use a simpler model.”
At the end of the competition, the final scores were as follows (with the scores achieved by the original researchers, for reference):
| Team | Score (RMSLE) |
| Original Researchers’ Score - Röding, M., Ma, Z. & Torquato | 0.025 |
| Data-SAVvy-Rocks | 0.0416 |
| NSS-RECODE | 0.0429 |
| mmkay | 0.0436 |
| Good_Cop_Bad_Cop | 0.0441 |
| PrMeaT | 0.0452 |
| SAM | 0.0483 |
While our private Kaggle competition did not offer a monetary reward, Data-SAVvy-Rocks definitely won bragging rights! Congrats Armelle Le Guelte, Savannah Sew-Hee, and Veronica Ikeshoji-Orlati.





